The Stanford Rapide Project

The Stanford Rapide Project |
|
The behavior of the architecture is dependent upon how its components behave individually, and how the components communicate to one another. The behavior of a component defines the relationship between the input the component reacts to and the output the component generates. Communication between the components must be made through connections that define the relationship between the output communication a component generates and the input communication the other components receive.
A behavior definition can be expressed in two ways: as a constraint and as an executable specification. Executable specifications are procedural processes that receive input and generate output communication. Constraint specifications (or constraints) are declarative conditions on the executable specifications. Constraint and executable specifications may be used, not only to define but also to analyze an architecture.
Comparative analysis of an architecture can be performed formally if the executable and constraint specifications are also formal. Such analysis is useful for several reasons:
Rapide will be used to illustrate these formal modelling concepts.
Rapide is an object--oriented executable architecture description
language designed for specifying and prototyping distributed, time--sensitive
systems. It separates a component's interface specification, e.g.,
the constituents by which the component communicates with other components,
from the component's executable specification, called its module.
A Rapide architecture consists of a collection of interfaces, a
collection of connections between the interfaces, and a set of formal constraints
that define legal and illegal behavior.
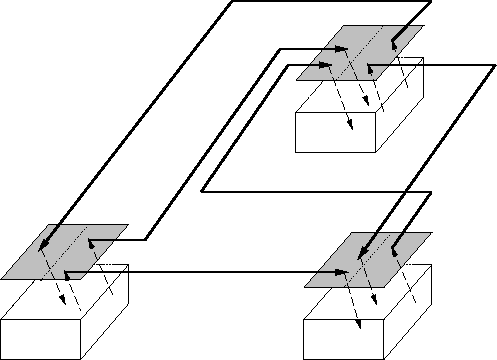
Figure 1: A Rapide architecture (top layer) and system (all).
Figure 1 shows a system of modules connected together in an architecture. The shaded parallelograms represent interfaces, the thick lines represent connections and the boxes represent modules. The architecture is shown as the set of interfaces and connections; the system is shown as the set of modules wired together by the architecture.
The reader may imagine an architecture executing by communication flowing up from the modules to their interfaces, along the architecture connections to other interfaces, and down into the receiving modules, and so on. Each module and connection can execute independently and concurrently. The communication at each interface must satisfy the constraints in the interface, and the communication in the connections must satisfy the architecture's constraints.
Rapide's execution model is based upon partially ordered sets of events (posets). The partial orders used are time and potential causality between events. Briefly, when a Rapide architecture executes it generates a poset. When an event is generated, it can produce a reaction in the connections and modules. Modules and connections will typically await the generation of some events and some condition of the program's state associated with those events, and then react to them. A module or connection reacts by executing some code that may include modifications to the program's state and the generation of additional events. Modules and connections often cycle through waiting, reacting, and generating events many times. The generated poset is checked for violations of the interface and architectural constraints.
The system in Figure 1 (i.e., the interfaces, connections, and modules) differs from a program written using Ada packages or C++ classes in that the modules communicate only if there are connections between their interfaces. In Rapide the architecture can be defined before the modules are written. It is a framework for composing modules, and it also constrains the communication between the modules of the system.
The system in Figure 1 can be written in Rapide to support different analysis methods. It can be executable to allow simulation and animation of the behavior of the architecture. It can also be a purely constraint--based definition of the allowable behavior of the system. Thirdly, the constraint--based definition can be used to check the architecture's behavior, as well as an actual implementation's behavior, for conformance to the constraints.
The rest of this document describes the underlying formalism of Rapide as well as the interface constituents that may be used to communicate with other components. The first section will address the formal computational model that is based upon event processing. The next section describes how to declare constituents of component interfaces. The basis for the architectural connections, executable and constraint specifications is the event pattern language described in this section. How to connect the component interfaces together into architectures is addressed in this Section. The individual components (and therefore the architectures) are executable, and this section describes the constructs used to associate executable specifications with component interfaces. Section describes the constraint specifications that are compiled into runtime monitoring code. Finally, section addresses how to relate architectures to one another using event pattern mappings.
In event--based approaches, such as Rapide, each event represents the occurrence of some activity within a program, e.g., an interaction between two components. Events are classified by actions and functions that define the kinds of activities that may occur during a distributed program's execution. Actions model asynchronous communication, and functions model synchronous communication between components. The execution of an action call will generate a single event, while a function's execution will generate two events, representing the call and return of the function. Thus, event--based models represent component interaction in a more natural and understandable manner than state--based models.
An event contains information such as the process and component generating the event, the name of the operation being invoked, and the data being passed.
The syntax for actions and functions is:
action_name_declaration ::=
action mode identifier
`(' [ formal_parameter_list ] `)' `;'
mode ::= in | out
function_name_declaration ::=
function identifier
`(' [ formal_parameter_list ] `)'
[ return type_expression ] `;'
For example,
action in Write(value : Data); function Read() return Data;Commentary: This example illustrates action and function declarations. It declares a Write action that contains a formal parameter of type Data, denoted by value, and a Read function that contains no formal parameters. A Write event with a value of 5 is generated when a process makes a call to the declared action passing 5 as a parameter, e.g., Write(5). Note the use of the action mode, in, will be explained in the action parts subsection of the section on types.
Pratt proposed models that can distinguish between concurrency and interleaving. These models are called event--based models with true concurrency. Instead of traces, these models are based upon partially ordered sets of events (or posets). Time is one such partial order. In time--based models, activities that occur before other activities are given lesser timestamps, while later activities are given greater timestamps. Concurrency is represented by sharing the same timestamp value.
Temporal poset models have a characteristic that make time an unpractical partial order for accurately representing concurrency; activities that are modelled with the same timestamp value may not have been concurrent. A single clock may produce timestamps that are not precise enough to distinguish concurrent from sequential activities. In this case, two events that are marked with the same timestamp value, may not have occurred concurrently. One may have represented an activity that preceded the other activity, but because the timestamp granularity was not fine enough, the two events were stamped with the same temporal value.
Additionally, distributed models may use more than one clock, each of whose timestamps are incomparable to the other clocks. In such situations, it is impossible to determine if events with incomparable timestamps actually occurred concurrently. Such a limitation usually leads the modeler to assume that incomparable timestamps implies concurrency.
Of course, a general solution to these two characteristics is to use one global, fine--grained clock. However, such a single, fine--grained clock model is not a practical starting point for representing distributed programs. Thus, a model of distributed programs that use only a temporal ordering, in general, is not an ideal choice, nor is it the only choices, to distinguish concurrency in distributed programs.
Another partial ordering used by Pratt to make the distinction between concurrency and interleaving is called causality. An event is caused by another if the first event could not have occurred without the occurrence of the second event. If there are two events that did not cause each other, they are said to be independent. Concurrency is defined to be causal independence in the poset, i.e., if two events occur independently in the causal partial order, they could have occurred concurrently in the execution.
It is best to use an event--based model that uses causality and time, since together these partial orders can naturally represent concurrency information between events that cannot be expressed by trace models. Additionally, the causal information is quite useful in analyzing program executions, and the causal dependency cannot be expressed in an obvious and understandable way using only traces, i.e., totally ordered sequences.
A partial order on a set S is an irreflexive, anti--symmetric and transitive relation « on the elements of S.
Note this document refers to the set on which the partial order relation is defined and the partial order relation, together, as a partial order. It will be clear from the context whether the relation or the set and the relation are meant.
A total order is a partial order that is also a total relation.
A total order on a set S is a partial order « on S such that if s_1 and s_2 are distinct elements in S then s_1 « s_2 or s_2 « s_1.
Rapide programs may contain multiple clocks, and a Rapide execution uses a separate temporal ordering to express timing between events with respect to each clock in the program. A consequence of the rules of time and dependency is that there is a consistency relation between the dependency order and temporal orders: an event cannot occur temporally earlier (by any clock) than an event that it depends on. Also, the various time orderings obey a consistency invariant: if event A temporally precedes event B for one clock, B cannot temporally precede A for another clock.
For example, please note the posets in Figures 2, 3 and 4 that respectively show for the same execution a timed poset, dependency poset, and a timed, dependency poset (the union of the timed and dependency posets).
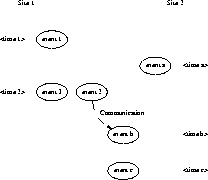
In the timed posets the timestamps of the site 1's (2's) events is denoted by a label to the left (right) of and parallel to the event's associated node. Thus, event 1 occurs at time 1, events 2 and 3 occur at time 2, event a at time a, event b at time b, and event c at time c.
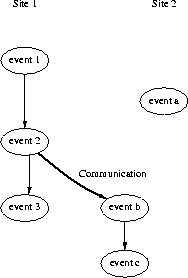

In the timed poset, the dashed arrow emphasises the fact that the dependency occurring because site 1 (event 2) communicates with site 2 (event b), is not representable in a model that only has time.
In the dependency poset, the following can be deduced for the dependencies: event 1 causally precedes event 2 that precedes both events 3 and b, and event b precedes event c. Event a could have executed concurrently with all of the other events. In this poset, the thick arrow emphasises that the communication dependency that was not representable in the timed poset is represented in this model.
In the timed, dependency poset, all of the previous information could have been determined. However, we are still unable to determine whether event 1 and event a occurred concurrently.
Interface types are declared using the following syntax:
type_declaration ::=
type identifier is interface_expression `;'
interface_type_expression ::=
interface { interface_constituent }
[ behavior behavior_declaration ]
end [ interface ] [ identifier ]
interface_constituent ::=
provides { interface_declarative_item }
| requires { interface_declarative_item }
| action { action_name_declaration }
| private { interface_declarative_item }
| service { service_declarative_item }
| constraint { pattern_constraint_list}
All modules of an interface type must contain types, modules, and functions
matching the declarations in the provides part, and these types,
modules, and functions are visible, which means that they may be
referred to outside the module. The constituents of a requires part
are names of components that are visible to the module but are not contained
within it. Those requires components are assumed to be contained
within another external module. The constituents of a private part
are only visible and used within modules of the interface type.
type Data_Object is interface provides Read : function() return Data; Write : function(d : Data); end interface Data_Object;Commentary: This example illustrates the use of provides constituents of an interface type. The interface type Data_Object contains two name declarations, Read and Write. Components of type Data_Object must contain actual objects (functions) with these names that other components may also use. Note that this interface has no requires or private parts.
For example,
type Data_Object_TC (type Data; init_val : ref(Data) is nil(Data)) is interface type Call_Type is enum Action_t, Function_t end enum; provides Read : function() return Data; Write : function(d : Data); action in Read_call(); out Read_retn(value : Data); in Write_call(value : Data); out Write_retn(); private action Read(c : Call_Type; value : Data; version : Integer); Write(c : Call_Type; value : Data; version : Integer; initial : Boolean); end interface Data_Object_TC;Commentary: This example illustrates the use of type constructors. Data_Object_TC is a type constructor. It has one type parameter Data that can be replaced by any type during application. A second, optional parameter init_val may be replaced by any reference to an object of the Data type. Data_Object_TC contains eight name declarations. The provides functions, Read and Write, will be associated with bodies defined by components whose type is constructed by an application of Data_Object_TC. Similarly, these components, whose type is constructed by an application of Data_Object_TC, must also define in actions, Read_call and Write_call, and they may generate the out actions, Read_retn and Write_retn. The private actions, Read and Write, are defined by and may only be used by Data_Object_TC components.
Note the Read and Write functions are not associated with the similarly named actions (Read_call, Read_retn, Write_call and Write_retn) by the semantics of functions and actions in the Rapide language.
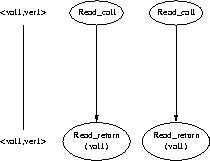
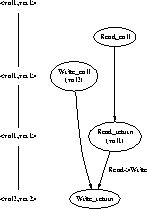

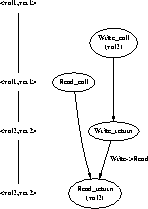
In a single--version semantic model, every read returns the value last written. Multiversion models provide increased concurrency by allowing multiple versions of an object to coexist; old versions of an object can still be read after a new version is written. This is exemplified in Figure 8. The value returned by the read in the figure is val2 which represents the single--version semantics. The multiversion semantics would allow the value returned to be either val2 or val1, the version before the write.
This section informally defines pattern specifications and gives examples of pattern specifications and operators. The formal definition of the pattern language may be found in the Patterns LRM.
Patterns may be constructed using the following syntax:
pattern ::=
basic_pattern
| `(' pattern `)'
| empty() | @ | any()
| pattern binary_pat_op pattern
| pholder_decl_list pattern
| `[' iterator_expression rel binary_pat_op `]'
pattern
| pattern where boolean_expression
| pattern_macro
binary_pat_op ::=
`->' | `||' | or | and | `~' | `<=>'
iterator_expression ::= `*' | `+' | expression
For example,
Read_retn(o)Commentary: This example illustrates the use of basic patterns. The pattern is only matched by Read_retn events whose first parameter is equal to the object ``o.''
Informal semantics for each combinator is given below.
Read_call -> Read_retn(o)Commentary: This example illustrates the use of dependent composite patterns. The pattern is only matched by a poset consisting of two events, a Read_call and a Read_retn event whose first parameter is equal to the object ``o.'' They are ordered in the poset, with the Read_call event causally preceding the Read_retn event.
Placeholders beginning with ``!'' are called universal placeholders because of their similarity to the logical quantifier forall. Universal placeholders are used in representing multiple instances of the pattern in which they occur, one instance for each object in the type of the universal placeholder. The operator in the universal placeholder declaration indicates the relationship the instances of the subpatterns have with each other. Placeholders may be declared in a pattern by giving a list of placeholder declarations, followed by a pattern.
The syntax of a placeholder declaration and placeholder declaration list is:
pholder_decl_list ::=
`(' pholder_decl { `;' pholder_decl } `)'
pholder_decl ::=
identifier { `,' identifier } : expression
| identifier : expression by operator
A poset C matches the pattern (?i : T) P(?i)
if there exists an object o whose type is (or is a subtype of
the type) defined by the expression T such that P(o)
is matched by C. A poset C matches the pattern (!i
: T by op) P(!i) if, where L
= [o_1, o_2, ...] is the list of objects whose type is (or is a subtype
of the type) defined by the expression T and poset C
matches P(o_1) op P(o_2) op ....
Placeholder declarations may appear within patterns so the replacement
can be restricted to subpatterns.
For example,
(!d : Integer range 1..10 by ->) Write_call(!d)Commentary: This example illustrates the use of universal placeholders. The universal placeholder !d is defined with respect to the binary pattern operator ->. This pattern is matched by a poset that contains ten totally ordered Write_call events, where each event's parameter, the universal placeholder !d, has a value in the integer range 1..10, and there is exactly one event for each value in the range.
`[' iterator_expression rel binary_pat_op `]' patternwhere iterator_expression is one of *, +, or n. Such a pattern is matched by iterator_expression, * (zero or more), + (one or more), and n (exactly n), matches of P, each match being related to the others by binary_pattern_operator.
For example,
[* rel ~] Read_retnCommentary: This example illustrates the use of iteration patterns. This pattern is matched by zero or more distinct Read_retn events. A poset consisting of three Read_retn events would actually contain eight matches for this pattern: one of size zero (the empty poset), three of size one, three of size two, and one of size three.
pattern_macro ::=
pattern identifier `(' [ macro_parameter_list ] `)'
is pattern `;'
macro_parameter_list ::=
macro_parameter { `;' macro_parameter }
macro_parameter ::=
type_parameter
| pattern identifier_list
Pattern macros serve several purposes. They may act as reusable patterns
to be used in more than one location. They also simplify patterns by breaking
them up into smaller units. Recursive macros allow the definition of patterns
that are otherwise inexpressible. Finally, new pattern operators can be
defined using macros (see the section on timing
operators).
For example,
pattern Ticks() is Tick -> Ticks();Commentary: Assume Tick is an action name. The pattern ``Ticks'' is an instance of the above macro. It describes an infinite chain of ordered Tick events. Pattern macros permit the description of infinite poset that are otherwise inexpressible. Iteration can only describe finite, though arbitrarily large poset.
pattern during(pattern P; T1,T2 : Integer; C : Clock ).The other temporal pattern operators are defined as:
pattern at(pattern P; T : Integer; C : Clock) is during(P,T,T,C); pattern before(pattern P; T : Integer; C : Clock) is (?F, ?L : Integer) during(P,?F,?L,C) where ?L <= T; pattern after(pattern P; T : Integer; C : Clock) is (?F, ?L : Integer) during(P,?F,?L,C) where ?F >= Time; pattern within(pattern P; T : Integer; C : Clock) is (?F, ?L : Integer) during(P,?F,?L,C) where (?L-?F <= T); pattern within(pattern P; T1, T2 : Integer; C : Clock) is (?F, ?L : Integer) during(P,?F,?L,C) where T1 <= ?L-?F and ?L-?F <= T2; pattern ``<''(pattern P1, P2; C : Clock) is (?F, ?L, ?F2, ?L2 : Integer) during(P1,?F,?L,C) ~ during(P2,?F,?L,C) where ?L1 < ?F2;For convenience, an infix shorthand is defined for the timing macros. Any timing macro of the form op(P,T1,T2,C) may be written as P op(T1,T2) by C, and op(P,T,C) may be written as P op T by C. If the clock C is omitted, the default clock is used.
For example,
Read_call < Read_retnCommentary: This example illustrates the use of the less than pattern operator that is defined by a pattern macro. The pattern is only matched by a poset consisting of two events, a Read_call and a Read_retn event. They are ordered in the poset, with the Read_call event temporally preceding the Read_retn event.
For example,
Read_call where state_value = 0Commentary: This example illustrates the use of a guarded pattern. The pattern is only matched by Read_call events that are generated when the value of state_value is equal to zero.
An architecture is a template for a family of systems. As an analogy, architectures can be viewed as printed circuit boards in which interfaces play the role of sockets into which component chips can be plugged, and connections play the role of wires between the sockets. Components communicate only if there are connections between their interfaces. Note: This notion of communication integrity is not enforced by the semantics of Rapide but rather via a particular style of writing Rapide programs. Thus, Rapide architectures are communication networks, defined independently of actual implementations. An architecture is declared in Rapide using the following syntax:
architecture_declaration ::=
architecture identifier `(' [ parameter_list ] `)'
[ return interface_expression ]
is
[ module_constituent_list ]
[ connect { connection } ]
end [ architecture ] [ identifier ] `;'
connection ::=
pattern connector pattern `;'
| other kinds of pattern connections ...
connector ::= `to' | `=>' | `||>'
Components can themselves be architectures. This provides a simple capability to develop a hierarchically structured architecture rather than one flat communication structure. When an interface in an architecture is associated with a module or another architecture, the resulting architecture is called an instance of the original one. The second (sub)module's interface or (sub)architecture's return interface expression must conform to (be a subtype of) the component interface it is being associated with. If omitted, the return interface expression of an architecture is the empty interface, called Root. Figure 1 depicted a fully instantiated architecture in which each interface has been associated with a module.
Similarly for functions, if a function is called and the function was declared as a constituent of a component interface's requires part, that function call will be compared will the architecture's connection rules. If the function call matches a connection's left--hand side, the connection will trigger, causing the function on the right--hand side to be called. The returned value from the right--hand side's call will be passed back to the original left--hand side's call as its return value. A component's requires function calls will be aliased to some other component's provides functions. Thus, connections define a flow of events and remote function calls between components.
A crucial point is that any connection only depends upon the interfaces of component modules of a system, and not upon the actual modules that might be implementing those interfaces. A connection can also relate events generated at the interface of the architecture to events at its components' interfaces, and conversely -- thus defining dataflow into and out of the architecture. If an architecture contains more than one connection, they will all trigger and execute concurrently.
Depending on the kind of connector used, e.g., basic, pipe or agent, the relationship between the events generated may vary. If the connector is basic (denoted by to) the generated event is causally and temporally equivalent to the event that matched the left--hand side. The pipe connection (denoted by =>) will result in the generated event causally following the triggering event, and causally following all events generated by previous executions of the connection. An agent connection (denoted by ||>) will also result in the generated event causally following the triggering event, but the connection doesn't causally relate the generated event to the events generated by previous executions of the connection.
For example,
connect AP.Read_call to Obj.Read_call;Commentary: This example illustrates the use of a basic connection. The left--hand side of the connection is a basic pattern that is only matched by Read_call events generated by the AP component. When such a match triggers the connection, a Read_call event will be generated and made available to the Obj component.
connect AP.Write to Obj.Write;Commentary: This example illustrates the use of function connections. The functions are declared in the interfaces of AP and Obj. The functions must be type-compatible. This connection has the effect that whenever AP calls its requires function Write, the call is executed as a call to Obj's provides function with the same arguments; the return values are returned to AP as the result if its call.
For example:
connect (?D : Data) AP.Write_call(?D) to Obj.Write_call(?D);Commentary: This example illustrates the use of patterns in connections. A requires action of the AP is connected to a provides action of the Obj. The syntax (?D : Data) declares the type of objects (Data) that may be bound to the placeholder ?D. In general, a pattern may be prefixed by a list of these placeholder declarations. The connection defines event flow between the AP and Obj; whenever the AP generates a Write_call event then the Obj will receive a causally and temporally equivalent Write_call event with the same data.
For example:
connect (?A : AP; ?D : Data) ?A.Write_call(?D) to [ !O : Data_Object_TC rel || ] !O.Request_Receive(?D);Commentary: The connection connects every AP to every Data_Object_TC. The connection triggers whenever any application program generates a Write_call event and results in generating Write_call events with the same Data (?D) at every module that is a subtype of Data_Object_TC. Each data object's Request_Receive event is dependent upon the application program's Write_call event, but is independent of any of the other data object's Request_Receive events.
The syntax for services is:
service_declaration_item ::= basic_name_list `:' [ dual ] interface_type_expression `;'Consider,
type Resource is interface service DO : Data_Object_TC(Integer); end interface Resource;The DO service in the Resource interface denotes all of the actions, functions and nested services (if any) constructed from applying Integer to the Data_Object_TC type constructor. To name them, the name ``DO'' is appended with the usual ``.'' notation before the name of the constituent. If the service were dual, the same constituents would be denoted except that the modes of the service's constituents are reversed; provides (requires) functions become requires (provides) functions, and in (out) actions become out (in) actions.
For example,
type Application is interface service DO : dual Data_Object_TC(Integer); end interface Application; architecture DTP_Architecture() is A : Application; RM : Resource; connect A.DO to RM.DO; end architecture DTP_Architecture;Commentary: Here the dual DO services of an Application and a Resource are connected by a single rule. This connection denotes the following set of basic connections between each pair of constituents with the same name in the two services:
A.DO.Read to RM.DO.Read; A.DO.Write to RM.DO.Write; P.DO.Read_call() to RM.DO.Read_call(); (?i : Integer) RM.DO.Read_retn(?i) to A.DO.Read_retn(?i); (?i : Integer) A.DO.Write_call(?i) to RM.DO.Write_call(?i); RM.DO.Write_retn() to A.DO.Write_retn();
service_set_declaration ::=
basic_name_list `(' { service_set_index } `)'
`:' [ dual ] interface_type_expression `;'
Service sets are connected to other services using connection generators.
The syntax for connection generators is:
connection_generator ::= generation_scheme generate connection end [ generate ] [ ( if | for ) ] `;' generation_scheme ::= if expression | for expression in expression next expression | for identifier `:' type_expression in expressionFor example,
type Application_Program(NumRMs : Integer) is interface service Rsrcs(1..NumRMs) : dual Data_Object_TC(Integer); end interface Application_Program; architecture DTP_Architecture(NumRMs : Integer) is AP : Application_Program(NumRMs); Rs : array[Integer] of Resource; connect for i : Integer in 1..NumRMs genereate AP.Rsrcs(i) to Rs[i].AP; end genereate; end architecture DTP_Architecture;Commentary: This example illustrates the expressive power of service sets and service set connections. The application program interface type constructor has a set of NumRMs dual data object services for communication with the resources labeled Rsrcs, and Rsrcs(i) is the ith data object service in the set. The architecture connects the application program AP to the array of resources Rs with a connection generator.
process ::= statement_list | generate_statementFor example,
for I : Integer in 1..NumObjs do DO(I).Write_call(0); end do;Commentary: This process consists of a single for statement. It makes Write_calls to several DO service set members, and then terminates. The Write_calls are all causally related in a total order.
Events are generated by a behavior or process through performing of action, function and patterns calls. The order of event generation is consistent with the causal and temporal orders. When an event is generated, it is immediately made available of that process. to other processes or connections. Constituents whose events are available to a process of a particular module are as follows: the in, private and internal actions of the module, and the out actions of constituent modules of the module.
Events are observed by a behavior, module, or process one at a time in some total order that is consistent with the causal and temporal orders. All processes share a consistent observation order. Also, a consistency relation holds between the observation and dependency orders, called the orderly observation principle: events are observed by a process one by one in some total order that is consistent with the dependency partial order.
The purpose of a timing clause is to model activities that have duration or occur some time in the future. Therefore, an event, which models a particular activity, has two timestamps: its start and finish times. A timing clause modifies the generation of an event by determining the start and finish timestamps.
A Rapide clock is a monotonically increasing counter. The rate at which it increases is not related to any physical unit, but rather is controlled by the program execution. This kind of clock provides what is oftern referred to as simulation time, as opposed to real--time. A clock's counter value is a timestamp, and an increase in time is referred to as a tick. A clock ticks when there are no more events to be generated with the current timestamp. A single Rapide architecture may contain multiple clocks, and an event may be timed with respect to one or more clocks.
The syntax for timing clauses is:
timing_clause ::= action_call pause timing_expression | action_call delay timing_expression | action_call in timing_expression timing_expression ::= expression | type_expressionA timing clause may only be applied to action calls, and it must include an expression. The timing expression may denote a single object or type. When an object is given, the object must be of type C.Ticks(Integer), and if a type is used, then it must be a subtype of C.Ticks, where C is called the named clock of the timing clause.
Timing clauses that use pause t will slow the execution of the action call for t ticks of the clock. That is, if the action call begins with the named clock's current counter value is n, then the call will complete when the counter value is n+t. The event will be generated and made available at timestamp n+t, and the start timestamp of the event will be n, while the finish timestamp will be n+t. Thus, the pause timing clause can be used to model the occurrences of activities that have duration.
A delayed action call is equivalent to the same call, substituting delay for pause, with the following exception. The action call will generate an event e with start timestamp n and finish timestamp n+t, and any event that is or becomes available to the process at timestamp s relative to the named clock, where n \leq s \leq n+t, will never be observed by the process executing the timing clause.
Timing clauses that use in t schedule the generation of the event for t ticks in the future. The start and finish timestamp of the event will both be n+t. If any of the timing clauses is parameterized with a value that is less than or equal to zero, it is equivalent to the same call without a timing clause. If a type expression is given, then it must be a subtype of C.Ticks for some clock C. Such a timing clause specifies an arbitrary value in the range of the type expression. That is an arbitray value in the range is selected, and if the range is empty, the predefined exception Timing_Error is raised.
For example,
Write_retn() in C.Ticks range 1..3;Commentary: This example statement schedules the generation of a Write_retn event 1, 2 or 3 ticks (non--deterministically chosen) in the future.
Note: Timed statements are very similar to timing clauses and enable a module to allow time to pass without generating an event. The effect of executing a timed statement is the same as executing an action call with an identical timing clause, except that no event is generated. The syntax for timed statements is:
timed_statement ::= pause timing_expression `;' | delay timing_expression `;'
await_stmt ::=
await pattern [ `=>' { stmt } pattern_choices
end [ await ] ] `;'
pattern_choices ::= { or pattern_choice }
pattern_choice ::= pattern `=>' { stmt }
when_stmt ::= when pattern do stmt_list end when `;'
The fundamental reactive statement is the await statement; the when
statement is a commonly used form of the await statement that has a special
syntax. An await statement includes one or more patterns that may be matched
by observed events; when a match of a pattern is observed, a (possibly
null) body of statements associated with that pattern, called its alternative,
is executed. If more than one pattern is matched by the observed events,
an arbitrary choice is made among the alternatives. The match of the pattern
chosen is said to trigger the execution of its alternative. The
scope of placeholders in an await statement's pattern extends to its alternative.
One can think of an await statement alternative as a parameterized list
of statements, such that upon observing a triggering match, an instance
of the alternative is execution, where the placeholder occurrences in the
alternative have been replaced by the substituting values determined in
matching.
For example,
await Read_call => Read(Action_t, $val, $ver) <=> Read_retn($val); or (?v : Data) [ * rel ~ ] Read_retn ~ Write_call(?v) => val := ?v; ver := $ver + 1; Write(Action_t, $val, $ver, False) <=> Write_retn(); end await;Commentary: This example consists of one await statement. In brief, the above statement waits for either a single, available and observed Read_call event or any number of available and observed Read_retn events and a Write_call event. If the Read_call event triggers, then a Read and a Read_retn event will be generated. The values of the parameters will be determined by dereferencing the (assumed) global val and ver reference objects. If the Read_retn and Write_call events trigger, then the two state assignments will be executed and a Write and a Write_retn event will be generated. The value assigned to val in the first assignment is equal to the value given the Write_call event that was bound in matching the pattern.
When statements are a special syntactic form of await statements; they model ``rules'' that fire repeatedly upon observation of a triggering match. The following when statement:
when pattern do stmt_list end when `;'is equivalent to:
loop do await pattern => stmt_list end await `;' end loop `;'For example,
when (?v : Data) [* rel ~] Read_retn ~ Write_call(?v) do val := ?v; ver := $ver + 1; Write(Action_t, $val, $ver, False) <=> Write_retn(); end when;Commentary: This example consists of one when statement. It repeatedly waits for any number of available and observed Read_retn and a Write_call event, performs two state assignments, and generates a Write and a Write_retn event in response to them.
For modules (see the section on module constructors), the earliest, maximal match (with that priority) among the pool will be used, and for behaviors (see the section on module behaviors), the first, earliest, maximal is used. If given all these rules, there more than one match, an arbitrary choice is made.
module_generator ::=
module identifier `(' [ parameter_list ] `)'
[ return interface_expression ] is
[ module_declaration_list ]
[ constraint module_pattern_constraint_list ]
[ connect module_connection_list ]
[ initial module_statement_list ]
[ ( parallel | serial )
process { `||' process } ]
[ final module_statement_list ]
end [ module ] [ identifier ] `;'
For example,
module Simple(type Data; init : ref(Data) is nil(Data)) return Data_Object(Data,init) is val : var Data; ver : var Integer := 0; Read : function() return Data is begin Read(Function_t,$val,$ver); return $val; end function Read; Write : function(value : Data) is begin val := value; ver := $ver + 1; Write(Function_t,$val,$ver,False); end function Write; connect (?v : Data) Read(Action_t,?v) to Read_retn(?v); (?v : Data; ?u : Integer) Write(Action_t,?v,?u,False) to Write_retn(); initial if not ( init.Is_Nil() ) then val := $init; Write(Action_t,$init,$ver,True); end if; parallel when Read_call do Read(Action_t,$val,$ver); end when; || when (?v : Data) [* rel ~] Read_retn ~ Write_call(?v) do val := ?v; ver := $ver + 1; Write(Action_t,$val,$ver,False); end when; end module Simple;Commentary: This example illustrates a module generator for the Data_Object_TC interface type declared in the section on type constructors. Simple defines two local variables, val and ver, that are not visible outside of this module generator. It also defines two functions that were declared provides in its interface. Functions can generate events as well as return values, and in this case, the functions generate events that are private -- because the associated actions were defined private in the interface.
Simple defines two connections. The first connection will generate a Read_retn event (via an out action call) every time a private Read event with an action_t Call_type is generated. Similarly, the other connection generates Write_retn events when Write events are generated.
When a module is initialized just after being created by an application of the module generator Simple, the module will test whether it has been given an initial value (init). If it has (init will not be Nil), the initial value will be store in the local variable val and a private Write event signifying this occurrence will be generated.
During execution the module may receive Read_call and Write_call
events. Upon observing a Read_call event, the module will generate
a private Read event, and upon observing a Write_call
event, the module will update its local variables representing its value
and version and generate a private Write event.

Figure 9: An Execution of a Module Constructed from Simple.
A possible execution of a module generated from an application of Simple is given in Figure 9. This execution features the execution of an application that initially issues a Read_call event. These requests were observed by the data object after the initial part of the object was executed and generated the Write(function_t,init_val,0,True) event. The data object's processing of the Read_call event causes the generation of a Read and a Read_retn event. Upon receiving the Read_retn event, the example application generates a Write_call and two more Read_call events. The data object observes and processes the events in the following order: i) one of the Read_call events, ii) the Write_call event, and iii) the other Read_call event. Every data object execution will produce the characteristic write, followed by a set of reads, followed by another write, as the object goes through its sequence of versions.
The syntax for module generators is:
behavior ::=
[ declaration_list ] begin { state_transition_rule }
state_transition_rule ::=
[ pholder_decl_list ] pattern op body `;'
op ::=
`=>' | `||>'
body ::=
[ { statement } ] [ poset_generator `;' ]
poset_generator ::= restricted_pattern
A state transition rule consists of an optional list of placeholder declarations
followed by a pattern, an op symbol, and a body. The
pattern found on the left side of the op symbol is called the
state transition rule's trigger. A transition rule defined using
the => op symbol is called a pipe, and one defined
using the ||> op symbol is called an agent.
A body consists of an optional set of statements followed by an optional restricted pattern that describes a set of posets (called a poset generator). The scope of the outermost placeholder declarations in the trigger extends throughout the body.
The default module is generated from an interface behavior via a fairly straight--forward translation with only minor semantic changes. Each state transition rule is translated into a repeating process that awaits the generation of a match for the trigger, and executes the body. As a generated module's processes execute, they are synchronized such that only one process may trigger and execute at a time. To determine which process to trigger, all of the matches for all of the pattern triggers are collected from the processes pools of available, observed events, and the first, earliest, maximal match (with that priority) is chosen (see the Section on triggers). Once an event participates in the triggering of a process (state transition rule), it becomes unavailable to that process, but will remain available to all of the others. Thus, an event may take part in triggering a given rule at most once, although it may participate in triggering several rules.
An action call statement in the body of a transition rule may include the in timing clause, but not the other timing clauses. A further restriction is that the pattern in the body may not contain the <=> operator.
For example,
behavior val : var Data; ver : var Integer := 0; Read : function() return Data is begin Read(Function_t,$val,$ver); return $val; end function Read; Write : function(value : Data) is begin val := value; ver := $ver + 1; Write(Function_t,$val,$ver,False); end function Write; begin Start => if not ( init.Is_Nil() ) then val := $init; Write(Action_t,$init,$ver,True); end if;; Read_call ||> Read(Action_t,$val,$ver) <=> Read_retn($val);; (?v : Data) [* rel ~] Read_retn ~ Write_call(?v) => val := ?v; ver := $ver + 1; Write(Action_t,$val,$ver,False) <=> Write_retn();;

In the case of distributed systems, constraints on causal event histories provide a powerful new kind of specification language. We argue, in fact, that this kind of specification language is necessary for expressing detailed requirements on distributed object systems. Prior experience with the Rapide constraint language has shown that constraint checking tools are effective and necessary in analyzing complex simulations for properties that are often too complex for the human viewer. Constraints may be utilized either to specify the behavior of single components, in which case they are part of interface definitions, or they can specify communication between objects, in which case they apply to architecture connections.
The behavior of Rapide program may be constrained by pattern constraints that are based upon pattern specifications. Pattern constraints denote the patterns of events and state that are acceptable and unacceptable.
Pattern constraints are satisfied by posets. If the poset is an instance of the pattern specification, the module's execution is said to satisfy the pattern specification.
Every pattern constraint is associated with a Rapide module and constrains only those events that were made available to it. For a pattern constraint occurring in an interface definition, each module of the interface must satisfy that constraint. For a pattern constraint occurring in a module generator, each module created by a call to the generator must satisfy the constraint.
pattern_constraint ::= [ label ] never pattern `;'No match of the given pattern should occur in the visible poset. If any such match exists, the constraint is violated.
pattern_constraint ::= [ label ] match pattern `;'A match constraint constrains a subset of the visible computation to match the given pattern. The computation constrained is all of the events associated with basic patterns occuring in the given pattern. This subcomputation must be an exact match of the pattern for the constraint to be satisfied.
The example below illustrates the never constraint. The constraint requires that two Write events whose initial parameters are true may not exist in an execution. This constraint expresses that a data object can only be initialized once.
never Write(initial is True) ~ Write(initial is True);Read returns are not necessarily ordered, while write returns are totally ordered. This is because writes must create a new version that must be causally after the preceding version, while there is no such constraint on reads. Note: versions are generated in a sequence.
match [* rel ->] Write_retn;A key property is that version numbers increase monotonically. Any two write returns must be causally ordered such that the version number of the dependent write return (?v2) must be greater than the version number of the preceding write return (?v1).
never (?v1, ?v2 : Integer) Write(version is ?v1) -> Write(version is ?v2) where ?v1 >= ?v2;If initially each object starts with a version number of 1 and each write increments the version number by 1, then at the leading edge of any consistent cut in the computation, the object's version number will be equal to the number of writes of that object before that edge.
match Write(version is 1, initial is True) -> [* rel ->] Write; match (?v : Integer) ( [* rel ->] Write -> Write(version is ?v) ) <=> [?v rel ->] WriteReads must return the last value written, and the versions must occur in sequences where a write occurs and is followed by any number of read returns that are followed by another version.
match [* rel ->] ((?d : Data)(?v : Integer) Write(?d,?v) -> [* rel ~] Read(?d,?v) );
Patterns provide the necessary expressive power to define hierarchical as well as non--hierarchical kinds of mappings. More generally, a map can interpret the executions of several architectures taken together (called domains) as executions of another range architecture. A significant benefit from interpreting domain executions as range executions is that the range execution generated by a map must satisfy the constraints of the range.
Moreover, maps are composable; maps can be domain parameters in the definition of other maps. Thus, maps can be used as constraints on their domains and as domain parameters of other maps.
map_generator ::=
map identifier `(' [ formal_parameter_list ] `)'
from domain_list
to range
is
{ declaration } [ constraint { constraint } ]
rule
{ agent_state_transition_rule }
end [ map ] [ name ] `;'
agent_state_transition_rule ::=
pattern `||>' { state_assignment } [ poset_generator ] `;'
The actual parameters of a map generator invocation must correspond to
the formal parameters of the map generator. These parameters serve the
same purpose as formal parameters of function calls, to pass data values
to the map generator. The data values passed are intended to be non--active
modules, i.e., modules that neither receive nor generate events.
While formal parameters are used to pass non--active modules, the list of domain indicators is used to pass active modules or maps. If the domain indicator is a type expression, then the actual domain must be a module (or map) whose interface type (or range type) must be a subtype of the domain indicator's type. If the domain indicator is a module generator name, then the actual domain must be a module generated from that module generator or a map whose range indicator is the same module generator.
Note: a map is not a module of its range interface type. It can't be connected to other components, and inputs can't be passed to it through the range. You can only pass in inputs to a map from its domain level. Maps do not react to events coming in from the range, only reacts from activity in the domain.
Since there are no real range constituents in a map, there is not an explicit range constituents' state. The map must provide the state by defining of constituents with the same name of the same type inside the map. If the constraints need values from a range constituent's state, the map will return the corresponding state from within the map.
Declaration of the range may be repeated in the map declarations. Maps may declare objects, and such objects are called state components. A map generator has visibility to the declarations in the interfaces of its domains and range, as well as the internal declarations of the module generators if the module generator name is the domain indicators. It can therefore name the actions of the interfaces of the domains and range as well as actions of their components.
The events that are made available to the map are as follows. If an actual domain of the map corresponds to an indicator that is a type expression, then the map observes the events of the requires and provides parts (but not a behavior part) of the domain's interface. If an actual domain of the map corresponds to an indicator that is a module generator, then the map observes the events generated in the domain if that event is generated by a call to an action or function of the domain's interface or its components' interfaces -- again only the requires and provides parts (not behavior part). If the actual domain is a map, then the map observes all events generated by the domain. Thus, a map can see inside (one level) of its domain objects, and all the way down inside another map.
The range actions called are limited to those in the range's interface type. That is, a map may call provides, requires and private actions of the range interface type, as well as provides, requires and private actions of modules declared in the range interface type. Maps may also explicitly call the implicitly declared call and return actions of functions.
The Rapide programmer has a choice among several induced orderings as defined below: For all events e, f generated in the range of some map, f depend upon e if and only if i) e and f were generated by the same rule, by the same triggering, and the poset generator in the body of the agent state transition rule specified f to depend upon e, or ii) T \induce U, where T is the domain poset that triggered e and U similarly triggered f. The following are the definitions of \induce that users may choose from:
Maps are intended to be used as an architecture analysis tool. An applications of maps has been to runtime compare an architecture with a standard (or reference) architecture. Comparison of architectures is accomplished by mapping the posets of the domain architecture(s) into behaviors of the range architecture and checking them for consistency with the constraints of the range architecture. Maps have also been established to reduce the complexity of large simulations by mapping posets of events in a detailed low--level simulation into single events in a higher level simulation.
When a hierarchical design methodology is used to develop a low level detailed architecture from a highly abstract specification, maps relating architectures at successive levels of abstraction can be composed transitively to define maps across several levels. Maps support consistency checking of architectures at different levels in a design hierarchy, and automated runtime comparison of an architecture with a standard (or reference) architecture.
Comparison of architectures is accomplished by mapping the behaviors of the domain architecture(s) into behaviors of the range architecture and checking them for consistency with the constraints of the range architecture.
Note: This tool is actually a translator that rewrites Rapide source into C++.
Animation is an aid to human understanding. It is a powerful tool in architecture prototyping. Often, in our experience with Rapide, animation of a simulation provides the easiest way for a user to assess what a system is doing. Only then is it possible to embark on a more formal process to modify the system, express constraints on its behavior, and so on. Also, animation of distributed systems is aided by causal histories, because the causal dependencies between events imply simple rules about the order in which events should be depicted to give an accurate animation.
The current simulation Rapide animator, called Raptor, consists of an active architecture-graphical event player that produces cartooned scenarios of a program execution. It provides a powerful demonstration facility to illustrate and communicate executions of the architecture. The event player depicts the architecture (currently statically) and gives a picture of who can communicate with whom. The tool is active in the sense that it is able to play back an execution of a program. It has been developed with an interface to causal event histories generated from any system, not only the Rapide simulator.
-C Tells raptor not to check the architecture file for semantic errors. The use of this option may cause raptor to be (more) unstable.
-D This option generates copious amounts of debuging info. Primarily of interest to developers.
-I filename This option instructs raptor to write the name of its tcl interpreter into file filename. See Section Raptor API for the use of this option.
-M X_display This option instructs raptor to connect to the computation manager running on the X display X_display. If multiple computation managers are running on that display than an aribitary one of them is chosen.
-N Tells raptor to NOT apply its heuristic techniques for determining sources and destinations of events. These heuristics are necessary for Rapide computations but are not necessarily needed for computations from other sources.
-S This option tells raptor not to instruct pov to display only the subset of events which will be animated. By default, that instruction is given.
-W This is an experimental option. It adjusts raptor's huristic for dealing with Rapide computations in such a way that if for favorable to computations which have fan-out basic connections but less favorable to computations which have chains of basic connections spanning hierarchy levels.
-Y This option tells raptor to show the time an event was generated. If the duration of the event is non-zero it is also shown. By default neither is shown. This option used to be -t and will be again when things get better.
-Z archname,zoomfactor Set the initial zoom level of the architecture archname to zoomfactor Multiple -Z options can be used to adjust the main and sub architectures. Note the use of the comma character as a separator.
-a architecture-file If an architecture-file is specified with this option, it is used as the definition of the archi- tecture. Otherwise, the archtecture file should be specified through the main menu.
-b Tells raptor to traverse the computation in a breadth first order.
-c value This option tells raptor how many steps to put between concurrent events. The default value is 25.
-p This option tells raptor to show the data parame- ters of events. By default they are not shown. This condition may also be toggled via the Options menu. See also the EVENT_PARAMETERS variable below.
-q This option instructs raptor to automatically terminate after animating a log file. This option is useful in scripted demos and is used in our regression testing mechanism.
-v Tells raptor to be verbose in describing where it is accessing files from. This is useful in debug- ing configuration problems.
-z value This option tell raptor at what speed to move the event boxs between modules. The value is expected to range from 0 (which, suprising is the fastest speed) to 500 (which is the slowest speed). The default value is 250. Just between you and me, the speed value is really the number of discrete steps the event box takes moving between modules.